
Трие

У рачунарству, трие, или често називано дигитално стабло и понекад радикс стабло или префиксно стабло (пошто се може претраживати по префиксу), је структура података у облику уређеног стабла које се користи за чување елемената динамичког скупа или асоцијативног низа где су кључеви обично ниске карактера. За разлику од бинарног стабла претраге, ниједан чвор у стаблу не чува кључ који одговара том чвору. Уместо тога, сама његова позиција у стаблу одређује кључ који му одговара. Сви наследници неког чвора имају заједнички префикс ниске карактера која одговара том чвору, а корену одговара празна ниска. Уобичајено је да се вредности не додељују сваком чвору већ само листовима и неким унутрашњим чворовима који одговарају траженим кључевима.
Термин трие потиче од енглеске речи retrieval. Овај термин је први пут употребио Едвард Фредкин, који га је изговарао као /ˈtriː/ енгл. tree као у речи retrieval.[1][2] Међутим, други аутори име ове структуре изговарају као /ˈtraɪ/ енгл. try, како би правили разлику од енгл. trее.[1][2][3]
У приказаном примеру, кључеви су део самих чворова а њихове одговарајуће вредности испод њих. Свака целовита реч има додељену произвољну целобројну вредност. Трие се може посматрати као детерминистички коначни аутомат без петљи. Сваки коначни језик се може генерисати трие аутоматом, и сваки трие се може сабити у Детерминистички ациклични коначни аутомат.
Није неопходно да кључеви буду експлицитно чувани у чворовима. (На слици, речи су приказане само како би се илустровао рад трие структуре).
Иако су код ове структуре, кључеви обично ниске карактер, не морају бити. Исти алгоритам се лако може адаптирати да обавља исте функције са уређеним листама било које конструкције, нпр. пермутације листе цифара или облика. Конкретно, битовски трие ради са кључевима у виду индивидуалних битова.
Примене
[уреди | уреди извор]Као замена за друге структуре података
[уреди | уреди извор]Као што се и у наставку помиње, трие има велики број предности у односу на бинарно стабло претраге.[4] Трие се такође може користити и као замена за хеш табелу у односу на коју има следеће предности:
- Претрага трие структуре је бржа и у најгорем случају, временске сложености О (м) (где је м дужина тражене ниске карактера), у односу на лошију хеш табелу. Лошија хеш табела може имати колизије кључева (хеш функција слика различите кључеве на исту позицију хеш табеле). У најгорем случају, претрага у лошијој хеш таблели је временске сложености О(N), али много чешће О(1) са временском сложеношћу О(м) евалуације хеш табеле.
- Не постоји колизија различитих кључева у трие.
- Простор за складиштење података са истим кључем је потребан само ако се подаци разликују.
- Нема потребе за хеш функцијом или за заменом хеш функције новом када се дода више кључева у трие.
- Трие може пружити алфабетско уређење вредности по кључу.
Код трие структуре података постоје и лоше стране:
- Трие може бити спорији од хеш табеле при претрази, посебно када су подаци чувани на дисковима са случајним приступом или другим уређајима секундарне меморије код којих је време случајног приступа велико у поређењу са главном меморијом.[5]
- Неки кључеви, као што су бројеви са покретним зарезом, могу довести до великих ланаца префикса који су бескорисни. Ипак, битовски трие може да ради са стандардом ИЕЕЕ.
- Неки трие може користити више меморије него хеш табела, јер се меморија алоцира за сваки карактер у траженој ниски карактера за разлику од једног парчета меморије које се алоцира код хеш табеле за ту исту ниску.
Представљање речника
[уреди | уреди извор]Честа примета трие структуре је чување предиктивног текста или речника са могућношћу аутоматског комплетирања речи, попут оних у мобилним телефонима. Таква примета користи могућност трие структуре да брзо пронађе, унесе и обрише вредност; ипак, ако је чување речи из речника све што је потребно (тј. ако није потребно чување додатних информација уз речи), минимални детерминистички ациклични коначни аутомат користи мање меморије него трие. То је због тога што ациклични детерминистички коначни аутомат може сабити идентичне гране стабла које одговарају истим суфиксима (или деловима) различитих речи које се чувају.
Трие се такође користи и код имплементације алгоритама приближног поређења[6], као и код провере правописа.
Алгоритми
[уреди | уреди извор]Лако се може описати претрага у трие структури. Нека трие има рекурзивно својство, у сваком чвору се налази листа трие потомака, индексирани следећим карактером у стрингу, а сваки чвор опционо садржи и вредност. Овде је овај тип података представљен у програмском језику Хаскел:
import Prelude hiding (lookup)
import Data.Map (Map, lookup)
data Trie a = Trie { value :: Maybe a,
children :: Map Char (Trie a) }
Вредност у трие можемо пронаћи на следећи начин
find :: String -> Trie a -> Maybe a
find [] t = value t
find (k:ks) t = do
ct <- lookup k (children t)
find ks ct
У императивном стилу, под претпоставком да већ постоји одговарајући тип података, може се описати исти алгоритам у програмском језику Пајтон. Притом, children представља мапу потомака чвора а крајњи чвор је онај који садржи валидну реч.
def find(node, key):
for char in key:
if char not in node.children:
return None
else:
node = node.children[char]
return node.value
Додавање новог елемента се одвија проласком кроз трие на основу ниске која се додаје а затим додавањем нових чворова за суфикс ниске који се не налази у трие-у. У императивном псеудокоду се то може представити на следећи начин:
algorithm insert(root : node, s : string, value : any):
node = root
i = 0
n = length(s)
while i < n:
if node.child(s[i]) != nil:
node = node.child(s[i])
i = i + 1
else:
break
(* dodaj nove cvorove ako je potrebno *)
while i < n:
node.child(s[i]) = new node
node = node.child(s[i])
i = i + 1
node.value = value
Сортирање
[уреди | уреди извор]Лексикографско сортирање скупа кључева се може постићи следећим алгоритмом базираном на трие структури:
- Убацити све кључеве у трие.
- Одштампати све кључеве из триа путем префиксног обиласка стабла, што чини да излаз буде у растућем лексикографском поретку
Овај алгоритам представља варијацију радикс сортирања.
Трие је основна структура података [[Бурстсорт]|буртсорта], који је (2007. године) био најбржи познати алгоритам за сортирање ниски карактера.[7] Ипак, данас постоје и бржи алгоритми за сортирање ниски карактера.[8]
Потпуно претраживање текста
[уреди | уреди извор]Посебна врста трие структуре, суфиксно стабло, може се користити у индексирању свих суфикса у тексту како би се применило брзо претраживање целокупног текста.
Битовски трие
[уреди | уреди извор]Битовски трие је сличан основном који је заснован на карактерима, осим што се у овом случају обилазак врши помоћу појединачних битова, чинећи структуру бинарним стаблом. Имплементације ове структуре користе посебне процесорске инструкције да се брзо пронађе бит првог скупа из кључа одређене дужине(нпр. код ГЦЦ преводиоца то је инструкција __builtin_clz()). Ова вредност се потом користи у индексирању табеле величине 32 или 64 која показује на прве елементе битовског трие-а са тим бројем водећих нула. Претрага се потом наставља уз провере сваког следећег бита из кључа и одабиром потомка child[0] или child[1] док се не нађе тражени елемент.
Иако овај процес звучи споро, због принципа локалитета и могућности ефикасног паралелизовања операција он заправо даје одличне перформансе на модерним процесорима. Тако рецимо, црвено-црно стабло даје много боље перформансе на папиру али у пракси не даје најбоље резултате управо како због ниске локалности (и самим тим лоше искоришћености кеша) тако и због тога што узрокује лошу искоришћеност проточне обраде. С друге стране, битовски трие ретко приступа меморији а када то уради, обавља само читање. Због тога, битовски трие све више постаје примарни избор у ситуацијама када се обавља доста додавања и брисања као што су меморијски алокатори (нпр. новије верзије чувеног dlmalloc алокатора и његобих потомака).
Пример имплементације битовског трие-а у језицима C и C++ може се наћи на адреси http://www.nedprod.com/programs/portable/nedtries/.
Компримовани трие
[уреди | уреди извор]Када је трие углавном статичан, тј. када се операције додавања и брисања елемената не користе већ се само извршава претрага и када су кључеви независни од вредности самих чворова могуће је компримовати представљање трие структуре спајањем истих грана.[9] Ова примена се углавном користи код компримовања табела претраживања када је укупан скуп смештених кључева врло проређен у односу на сам простор података.
На пример, може се користити за представљање проређених скупова битова (нпр. подскупови много већих фиксних набројивих скупова) користећи трие чији су кључеви позиције битовских елемената у целокупном скупу и то тако да се кључеви добијају од ниске карактера битова која је неопходна за кодирање позиције сваког елемента. Трие ће тада имати дегенерисан облик са недостајућим гранама, а компресија се омогућава чувањем листова стабла (делови скупа са фиксираном дужином) и њиховим комбиновањем када се установи да садрже исте делове или попуњавањем одговарајућих празнина.
Овакво компримовање се такође користи и у имплементацијама разних табела за брзу претрагу које враћају карактеристике Уникод карактера (нпр. табеле претраге које садрже комбинације базних и комбинованих карактера који су потребни у нормализацији Уникода). За такве примене, репрезентација је слична трансформисању великих једнодимензионих ретких табела у вишедимензионе матрице а потом коришћење координата хипер-матрице као стринг кључ некомпримованог трие-а. Компримовање тада подразумева проналажење и спајање истих колона хипер-матрице како би се компримовала последња димензија у кључу; свака димензија хипер-матрице садржи почетну позицију у вектору следеће димензије за вредност сваке координате, а резултујући вектор се може компресовати ако је такође редак, тако да се свака димензија (везана за један ниво у трие-у) може компримовати посебно.
Неке имплементације подржавају такве компресије у динамичком ретком трие-у са омогућеним уношењем и брисањем елемента трие-а. Овакве имплементације имају значајан трошак при растављању и спајању грана, а одређени уступци се праве између најмање величине компресованог трие-а и брзине ажурирања, ограничавајући глобалну претрагу за упоређивање истих грана у ретком трие-у.
Резултат такве компресије може деловати слично као трансформисање трие структуре у усмерени ациклични граф, јер реверзна трансформација таквог графа у трие је очигледна и увек могућа, ипак она је ограничена обликом кључа којим се индексирају чворови.
Један од других начина компресије је пресликавање структуре података у низ бајтова.[10] Овај приступ елиминише потребу за показивачима на чворове што знатно смањује меморијске захтеве и омогућава мапирање меморије што даље доводи до много ефикаснијег учитавања података у меморију.
Још један приступ компримовању је тзв. „паковање“ трие-а.[2]
Предности у односу на друге алгоритме претраге
[уреди | уреди извор]- Графички приказ понашања различитих алгоритама у односу на број елемената
-
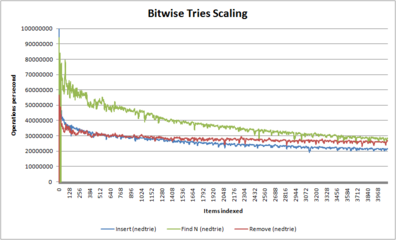 Понашање Фредкин трие структуре као функција величине
Понашање Фредкин трие структуре као функција величине
(у овом случају, недтрие структуре, што подразумева имплементацију у месту, што узрокује да има знатно стрмију криву у односу на динамичке имплементације трие-а) -
 Понашање црвено-црних стабала као функција величине
Понашање црвено-црних стабала као функција величине
(у овом случају, BSD имплементацијаrbtree.h, која показује класичноO(log N)понашање) -
 Понашање хеш табеле као функција величине
Понашање хеш табеле као функција величине
(у овом случају,uthash, која у просеку испољава понашање сложеностиO(1))



За разлику од већине други структура података, трие има чудну особину да је сложеност кода, а самим тим и потребно време, скоро идентично за операције додавања, брисања и претраживања. Као резултат тога, у ситуацијама када код врши додавање, брисање и проналажење елемената у једнакој мери, трие може лако победити бинарно стабло претраге. С друге стране, ова трие структура омогућава бољу подлогу за ефикасно кеширање процесорских инструкција и гранања.
Главне предности трие структуре над бинарним стаблом претраге (БСП):
- Операција претраге кључева је бржа. Претрага кључа дужине m има временску сложеност О(m). БСП врши О(log(n)) поређења кључева, где је n број елемената стабла, јер претрага зависи од висине стабла које је логаритамско ако је стабло балансирано. Стога, у најгорем случају, претрага у БСП има О(м лог н) временску сложеност. Такође, операције које користи трие при претрази (приступ низу преко индекса који је карактер) су брзе на реалним машинама.
- Трие је просторно ефикаснија структура када садржи велики број кратких кључева, јер су чворови заједнички кључевима са истим префиксима.
- Трие олакшава проблем најдужег заједничког префикса.
- Број унутрашњих чворова од корена до листова је једнак дужини кључа, тако да нема потребе за балансирањем стабла.
Главне предности трие-а над хеш табелом су:
- Трие подржава уређене итерације док су итерације над хеш табелом у псеудо-случајном поретку, што зависи од хеш функције као и решавања колизија (што је одређено имплементацијом)
- Трие олакшава проблем најдужег заједничког префикса.
- Трие је у просеку бржи при уношењу елемента од хеш табеле јер хеш табела мора да преправи индексе када се напуни, што је скупа операција. Трие стога има боље ограничену временску сложеност у најгорем случају.
- За кључеве мање дужине, трие је бржи јер нема коришћења хеш функције.
Види још
[уреди | уреди извор]Референце
[уреди | уреди извор]- ^ а б Black, Paul E. (16. 11. 2009). „trie”. Dictionary of Algorithms and Data Structures. National Institute of Standards and Technology. Архивирано из оригинала 25. 01. 2009. г. Приступљено 03. 01. 2014.
- ^ а б в Franklin Mark Liang (1983). Word Hy-phen-a-tion By Com-put-er (PDF) (Теза). Stanford University. Архивирано (PDF) из оригинала 19. 05. 2010. г. Приступљено 28. 3. 2010.
- ^ Knuth 1997, стр. 492
- ^ Bentley, Jon; Sedgewick, Robert (1. 4. 1998). „Ternary Search Trees”. Dr. Dobb's Journal. Dr Dobb's. Архивирано из оригинала 23. 6. 2008. г.
- ^ Fredkin, Edward (1960). „Trie Memory”. Communications of the ACM. 3 (9): 490—499. S2CID 15384533. doi:10.1145/367390.367400.
- ^ Aho, Alfred V.; Corasick, Margaret J. (1975). „Efficient string matching”. Communications of the ACM. 18 (6): 333—340. S2CID 207735784. doi:10.1145/360825.360855.
- ^ „Cache-Efficient String Sorting Using Copying” (PDF). Архивирано из оригинала (PDF) 01. 10. 2007. г. Приступљено 15. 11. 2008.
- ^ Kärkkäinen, Juha; Rantala, Tommi (2008). Engineering Radix Sort for Strings. (PDF). Lecture Notes in Computer Science. 5280. стр. 3—14. ISBN 978-3-540-89096-6. doi:10.1007/978-3-540-89097-3_3. Приступљено 11. 3. 2013.
- ^ Daciuk, Jan; Stoyan Mihov; Watson, Bruce W.; Watson, Richard E. (2000). „Incremental Construction of Minimal Acyclic Finite-State Automata”. Computational Linguistics. Association for Computational Linguistics. 26: 3—16. S2CID 3265924. doi:10.1162/089120100561601. Архивирано из оригинала 30. 09. 2011. г. Приступљено 28. 5. 2009. „This paper presents a method for direct building of minimal acyclic finite states automaton which recognizes a given finite list of words in lexicographical order. Our approach is to construct a minimal automaton in a single phase by adding new strings one by one and minimizing the resulting automaton on-the-fly”
- ^ Germann, Ulrich; Eric Joanis; Larkin, Samuel (2009). „Tightly packed tries: how to fit large models into memory, and make them load fast, too” (PDF). ACL Workshops: Proceedings of the Workshop on Software Engineering, Testing, and Quality Assurance for Natural Language Processing. Association for Computational Linguistics. стр. 31—39. „We present Tightly Packed Tries (TPTs), a compact implementation of read-only, compressed trie structures with fast on-demand paging and short load times. We demonstrate the benefits of TPTs for storing n-gram back-off language models and phrase tables for statistical machine translation. Encoded as TPTs, these databases require less space than flat text file representations of the same data compressed with the gzip utility. At the same time, they can be mapped into memory quickly and be searched directly in time linear in the length of the key, without the need to decompress the entire file. The overhead for local decompression during search is marginal.”
Литература
[уреди | уреди извор]- Knuth, Donald (1997). „6.3: Digital Searching”. The Art of Computer Programming Volume 3: Sorting and Searching (2nd изд.). Addison-Wesley. стр. 492. ISBN 978-0-201-89685-5.
- de la Briandais, R. (1959). „File Searching Using Variable Length Keys”. Proceedings of the Western Joint Computer Conference: 295—298.