У инферацијалној статистици, појам грешке првог типа се односи на погрешно одбацивање тачне нулте хипотезе (такође се назива лажно позитиван закључак; на пример осудити недужну особу), док се грешка другог типа односи на неуспех одбацивања истински погрешне нулте хипотезе (назива се и лажно негативним закључком; на пример не осудити злочинца)[1]. Велики део статистике се заснива на смањивању једног или оба типа наведених грешака, и ако је сигурно одбацивање било које од њих статистички немогуће (без познавања узрочног процеса). Одабиром ниске границе одсецања и модификацијом алфа(α) нивоа, квалитет теста се може повећати.
Грешке првог типа се интуитивно могу посматрати као грешке извршења, односно, истраживач није имао среће са околностима експеримента те је погрешно донео закључак да је хипотеза коју доказује истинита. Примера ради, размотримо како би се могло проверити дејство новог лека. Уколико лек у стварности не ради ништа али се тестирањем сасвим случајно задеси да испитаници којима је дат тај лек оздраве брже од оних којима није, то би нас навело на закључак да лек заиста ради, и ако то није случај. Аналогно, грешке другог типа се могу сматрати грешкама изостављања. У претходном примеру, то би био случај у којем, и ако лек заиста служи својој сврси, нисмо приметили значајну разлику између група испитаника те донели закључак да нови лек није добар.
Овај чланак је део пројектасеминарских радова на Математичком факултету у Београду. Датум уноса: март—јун 2022. Ова група студената уређиваће у простору чланака. Немојте пребацивати чланак у друге именске просторе. Позивамо вас да допринесете његовом квалитету и помогнете студентима при уређивању.
У инференцијалној статистици, појам статистичке грешке је кључан део тестирања хипотеза. Тестирање укључује бирање између две конкурентне пропозиције, нулте хипотезе која се означава са H0 и алтернативне хипотезе која се означава са H1. Ово је концептуално слично судској пресуди. Нулта хипотеза одговара ставу окривљеног: као што се сматра да је он невин док се не докаже да је крив, тако се претпоставља да је нулта хипотеза тачна док подаци убедљиво докажу да није. Алтернативна хипотеза одговара ставу против окривљеног. Тачније, нулта хипотеза такође укључује одсуство разлике или одсуство повезаности. Дакле, нулта хипотеза никад не може бити да постоје разлике или повезаности.
Ако резултат теста одговара стварности, онда је донета исправна одлука. Ипак, ако резултат тестирања не одговара стварности, онда је дошло до грешке. Постоје две ситуације у којима одлука није исправна. Нулта хипотеза може бити тачна, док одбацујемо H0. С друге стране, алтернативна хипотеза може бити тачна, док не одбацујемо H0. Разликујемо два типа грешке: грешка типа I и грешка типа II.[2]
Прва врста грешке је погрешно одбацивање нулте хипотезе као резултат процедуре тестирања. Ова врста грешке се назива грешка типа I (лажно позитивно) и понекад се назива грешка прве врсте. У примеру судске процедуре, грешка типа I одговара осуди оптуженог који је заправо невин.
Друга врста грешке је погрешан неуспех да се одбаци нулта хипотеза као резултат процедуре тестирања. Ова врста грешке се назива грешка типа II (лажно негативно) и понекад се назива грешка друге врсте. У примеру судске процедуре, грешка типа II одговара ослобађању криминалца. [3]
Стопа грешке преласка је тачка у којој су грешке типа I и грешке типа II једнаке. Систем са ниском вредности стопе грешке преласка обезбеђује више тачности него систем са високом вредности стопе грешке преласка.
У смислу лажних позитивних и лажних негативних резултата, позитиван резултат одговара одбацивању нулте хипотезе, док негативан резултат одговара неуспешном одбацивању нулте хипотезе; „нетачно“ значи да је закључак погрешан. Дакле, грешка типа I је еквивалента лажном позитивном резултату, а грешка типа II је еквивалентна лажном негативном.
Савршен тест би имао нула позитивних и нула негативних грешака. Међутим, статистичке методе су вероватноће и не можемо бити сигурни да ли су статистички закључци тачни. Где год постоји несигурност, ту је и могућност прављења грешке. Посматрајући ову природу статистичке науке, сви тестови статистичких хипотеза имају вероватноћу прављења грешака I и II типа.
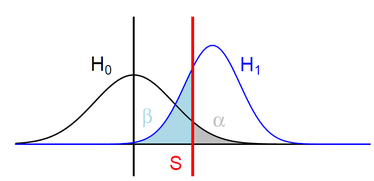
График зависности грешке првог и другог типаСтопа грешке типа I је вероватноћа одбацивања тачне нулте хипотезе. Тест је дизајниран да стопу грешке типа I држи испод унапред дефинисане границе назване ниво значајности, обично означаване грчким словом α (алфа) и такође називане алфа ниво. Обично, овај ниво је подешен на 0,05 (5%), подразумевајући да је прихватљиво имати 5% вероватноће да се нетачно одбаци тачна нулта хипотеза.[5]
Стопа грешке типа II означена је грчким словом β (бета) и повезана са моћи теста, што је једнако 1 - β.
Ова два типа стопа грешака међусобно мењају вредности: за било који дати скуп узорака, напор да се смањи једна грешка доводи до повећања друге.
Иста идеја може бити изражена у смислу стопе тачности резултата, те се стога користи за умањивање грешака и побољшања квалитета тестова хипотеза. Да би смањили вероватноћу од доласка до грешке типа I, једноставније је и ефикасније алфа вредност учинити строжијом. Да би умањили вероватноћу прављења грешке типа II, што је ближе повезано са моћи анализе, потребно је или увећати величину узорка теста или опустити алфа ниво што може повећати моћ анализе. Статистика теста је јака ако се контролише стопа грешке типа I.
Различитим вредностима прага се такође може користити да тест учини или специфичнијим или осетљивијим, што за узврат повећава квалитет теста. На пример, замислимо медицински тест, у ком би особа која врши експеримент могла да мери одређену концентрацију протеина у узорку крви. Она би могла да прилагоди праг и људима би могла да се дијагностикује болест уколико би се очитала било која бројка изнад овог прага.
Будући да је у правом експерименту немогуће да се избегну све грешке првог и другог типа, треба узети у обзир количину ризика који смо спремни да прихватимо да погрешно одбијемо H0 или прихватимо H0. Решење је да забележимо p-вредност или ниво значајности α прорачуна. На пример, ако је p-вредност процењена на 0.0596, онда је шанса 5.96% да смо погрешно одбацили H0. Или, ако кажемо да је стастика спровођена на нивоу α, ако је 0.05, онда дозвољавамо да погрешно одбацимо H0 у 5% случајева. Ниво значајности од 0.05 је релативно уобичајен, али не постоји опште правило које одговара свим случајевима.
Ограничење брзине на аутопуту у Сједињеним Америчким Државама је 120 километера по часу. Уређај је намештен да мери брзину возила које пролазе. Рецимо да тај уређај спроводи три мерења брзине возила који прође, X1, X2, X3. Саобрачајна полиција ће одлучити да ли да казни возача или не у зависности од просечне брзине . Другим речима од статистике теста
Додатно, претпоставимо да мерења X1, X2, X3 прате нормалну расподелу N(μ,4). Онда би Т пратило N(μ,4/3), где је μ права вредност брзине, а варијанса је смањена три пута јер узимамо просек три мерења. У овом експерименту, нулта хипотеза је , алтернативна хипоетеза . Ако радимо прорачун на нивоу α=0.05, критична вредност c се рачуна решавањем
Ово значи да ако је измерена просечна брзина возила већа од 121.9, возач ће бити кажњен. Ипак, 5% од њих ће бити погрешно кажњени јер је измерена просечна брзина већа од 121.9, али реална брзина није већа од 120, што је грешка првог типа.
Грешка другог типа одговара случају када права брзина превазилази 120 километеара по часу, али возач није кажњен. На пример, ако је реална брзина , шанса да возач неће бити ухваћен са рачуна као
што значи да ако је права брзина возила 125, а прорачун се ради на нивоу 0.05, возач има шансу од 0.36% да избегне казну јер је просечна брзина од оних забележених у три момента мања од 121.9. Са повећањем реалне брзине, шанса за грешку се смањује.
У 1928 години, Џерзи Неиман (1894-1981) и Егон Пирсон (1895-1980), истакнути статистичари, дискутовали су о проблему о „одлучивању да ли се одређеном узораку може пресудити да је вероватно насумично изабран из одређене популације“[6] и, нагласио је Флоренс Најтингејл Давид, „обавезно је нагласити придев насумично се односи на методу узимања узорка а не на сам узорак“.[7]
Установили су „два извора грешака“:
(а) одбацивање хипотезе коју није требало одбацити
(б) не одбацивање хипотезе коју је требало одбацити
У 1930 години, појаснили су ова два извора грешака,приметивши:
....у тестирању хипотеза две ствари се морају имати у виду, морамо да смањимо шансу одбацивања тачне хипотезе на најмању жељену вредност. Тест мора бити осмишљен тако да ће одбацити тестирану хипотезу ако је вероватно да је она нетачна.
У 1933 години, приметили су да ови „проблеми су ретко представљени у форми тако да можемо да разликујемо између тачне и нетачне хипотезе“. Такође су додали да у одлучивању да ли одбити одређену хипотезу у „групи алтернативних хипотеза“, H1, H2.... веома је лако направити грешку.
.... и ове грешке ће имати две врсте:
(1) одбијамо H0 (хипотеза која ће се тестирати) када ће бити тачна[8]
(2) не успевамо да одбијемо H0 када је нека алтернативна хипотеза HА или H1 тачна
У свим текстовима чији су коаутори Неиман и Пирсон H0 представља хипотезу која ће бити тестирана. У истим текстовима они ова два извора грешака називају грешкама типа 1 и типа 2 редом.[9]
Уобичајено је да статистичари спроводе тестове како би утврдили да ли се може подржати „спекулативна хипотеза“ о посматраним феноменима света (или његовим становницима). Резултати таквог тестирања одлучују да ли се одређени скуп резултата логицки слаже (или се не слаже) са спекулисаном хипотезом.
На основу тога што се увек претпоставља, по статистичкој конвенцији, да је спекулисана хипотеза погрешна, И да је такозвана „нулта хипотеза“, да се посматрани феномени једноставно јављају случајно (и да, као последица тога, спекулисани агенс нема ефекат). Тест ц́е утврдити да ли је ова хипотеза тачна или погрешна. Због овога се хипотеза која се тестира често назива нултом хипотезом (највероватније ју је назвао Фишер(1935, п. 19)), јер се управо та хипотеза или треба поништити или не поништити тестом. Када се нулта хипотеза поништи, могуц́е је закључити да подаци подржавају „алтернативну хипотезу“ (првобитно спекулисану).
Константна примена Нејманове и Пирсонове конвенције од стране статистичара о представљању „хипотезе коју треба тестирати“ (или „хипотезе која се поништава“) са изразом H0 довела је до околности у којима многи схватају термин „нулта хипотеза“ као „ нул хипотеза“ – изјава да су дотични резултати настали случајно. Ово није нужно случај – кључно ограничење, према Фишер-у (1966), је да „нулта хипотеза мора бити тачна, ослобођена нејасноц́а и двосмислености, јер мора представљати основу 'проблема дистрибуције,' чије је решење тест значаја.“[10] Као последица овога, у експерименталној науци нулта хипотеза је генерално изјава да одређени третман нема ефекта; у науци о посматрању, то је да не постоји разлика између вредности одређене мерене варијабле и вредности експерименталног предвиђања.
Ако је вероватноц́а добијања резултата екстремног као што је добијен, под претпоставком да је нулта хипотеза тачна, мања од унапред одређене граничне вероватноц́е (на пример, 5%), онда се за резултат каже да је статистички значајан а нулта хипотеза се одбацује.
Британски статистичар Сер Роналд Ајлмер Фишер (1890–1962) нагласио је да је „нулта хипотеза“:
... никада није доказана или утврђена, али је могуц́е оспорена, током експериментисања. За сваки експеримент се може рец́и да постоји само да би се чињеницама дала прилика да оспоре нулту хипотезу.
Хипотеза: „Новорођенчад имају фенилкетонурију и хипотиреозу“.
Нулта хипотеза (H0): „Новорођенчад немају фенилкетонурију и хипотиреозу“.
Грешка типа I (лажно позитивно): Чињеница је да новорођенчад немају фенилкетонурију и хипотиреозу, али према подацима сматрамо да имају те поремећаје.
Грешка типа II (лажно негативно): Чињеница је да новорођенчад имају фенилкетонурију и хипотиреозу, али према подацима сматрамо да немају те поремећаје.
Иако показују високу стопу лажно позитивних резултата, скрининг тестови се сматрају вредним јер у великој мери повећавају вероватноћу откривања ових поремећаја у далеко ранијој фази.
Једноставни крвни тестови који се користе за скрининг могућих давалаца крви на ХИВ и хепатитис имају значајну стопу лажно позитивних; међутим, лекари користе много скупље и далеко прецизније тестове како би утврдили да ли је особа заиста заражена било којим од ових вируса.
Можда најчешће дискутовани лажно позитивни резултати у медицинском скринингу потичу од процедуре скрининга рака дојке, мамографије. Стопа лажно позитивних мамографија у САД-у је до 15%, што је највише у свету. Једна од последица високе стопе лажно позитивних резултата у САД-у је да, у било ком периоду од 10 година, половина жена које су прегледане добију лажно позитиван мамограф. Лажно позитивни мамографи су скупи, више од 100 милиона долара се годишње троши у САД-у на накнадно тестирање и лечење. Они такође изазивају непотребну анксиозност код жена. Као резултат високе стопе лажно позитивних резултата у САД-у, чак 90-95% жена које добију позитиван мамограф немају рак дојке. Најнижа стопа на свету је у Холандији, 1%. Најниже стопе су генерално у северној Европи где се мамографски резултати читају два пута и поставља се високи праг за додатно тестирање (високи праг смањује снагу теста).
Идеалан скрининг тест популације био би јефтин, лак за примену и давао би нула лажно негативних резултата, ако је могуће. Такви тестови обично дају више лажно позитивних резултата, који се накнадно могу разврстати елегантнијим (и скупљим) тестирањем.
Тестирање подразумева далеко скупље, често инвазивне процедуре које се дају само онима код којих се манифестује нека клиничка индикација болести, а најчешће се примењују за потврду сумње на дијагнозу.
Лажно негативни и лажно позитивни резултати су значајни проблеми у тестирању.
Грешка типа I (лажно позитивно): Чињеница је да пацијенти немају одређену болест, али лекари процењују да је пацијенти имају према извештајима испитивања.
Лажно позитивни резултати могу изазвати озбиљне и контраинтуитивне проблеме када је стање које се тражи ретко. Ако тест има лажно позитивну стопу од један од десет хиљада, али је само један од милион узорака (или људи) истински позитиван, већина позитивних резултата откривених тим тестом биће лажна. Вероватноћа да је уочени позитиван резултат лажно позитиван може се израчунати коришћењем Бајесове теореме.
Грешка типа II (лажно негативна): Чињеница је да је болест заиста присутна, али извештаји о тестовима пружају лажно уверавајућу поруку пацијентима и лекарима да је та болест одсутна.
Лажно негативни резултати такође стварају озбиљне и контраинтуитивне проблеме, посебно када је стање које се тражи често. Ако се тест са стопом лажно негативних резултата од само 10% користи за тестирање популације са правом стопом појављивања од 70%, многи негативни резултати које је тест открио биће лажни.
То понекад доводи до неодговарајућег или неадекватног третмана како пацијента тако и његове болести. Уобичајени пример је ослањање на срчане стрес тестове за откривање коронарне атеросклерозе, иако је познато да тестови срчаног стреса откривају само ограничења протока крви у коронарној артерији због узнапредовале стенозе.
Биометријско скенирање, као нпр. за препознавање отиска прста, препознавање лица или препознавање дужице ока, је склоно грешкама I и II типа.
Хипотеза: „Унос не идентификује некога у претраженој листи људи“.
Нулта хипотеза: „Унос идентификује некога у претраженој листи људи“.
Грешка типа I (false reject rate wip): „Чињеница је да особа јесте неко у претраженој листи али систем закључује да особа није према подацима".
Грешка типа II (false match rate wip): „Чињеница је да особа није неко у претраженој листи али систем закључује да је особа неко кога тражимо према подацима“.
Вероватноћа грешки типа I назива се „false reject rate“ (FRR) wip или false non-match rate (FNMR) wip, док се вероватноћа грешки типа II назива „false accept rate“ (FAR) wip или false match rate (FMR) wip.
Ако је систем дизајниран да ретко проналази осумњичене, његова вероватноћа грешки типа II се мозе звати „мера лажних аларма“. Са друге стране, ако се систем користи за валидацију (и прихватање је очекивано) онда је FAR wip мера безбедности система, док је FRR wip мера неугодности корисника.
Лажни позитиви се свакодневно виђају у аеродромским безбедносним прегледима. Инсталирани безбедносни аларми имају за циљ да спрече уношење оружја у авион, али су често тако осетљиви да алармирају више пута дневно за небитне ствари, као што су кључеви, копче на каишевима или мобилни телефони.
У овом случају, нулта хипотеза је „предмет није оружје", док је хипотеза „предмет јесте оружје“.
Грешка типа I (лажно позитивно): „Чињеница је да предмет није оружје али аларм ипак звони“.
Грешка типа II (лажно негативно): „Чињеница је да је предмет оружје али аларм тренутно не звони“.
Однос лажних позитивних резултата (идентификовање невиног путника као терористу) са тачним позитивним резултатима (детектовање терористе) је, дакле, веома висок; и зато што је скоро сваки аларм лажни позитив, positive predictive value wip ових тестова је веома ниска.
Цена лажних резултата даје разлог зашто креатори тестова допуштају овакав однос. Будући да је цена лажно негативног резултата у овом сценарију веома висока (неоткривање бомбе или оружја које се уноси у авион може довести до стотина смртних случајева) док је цена лажног позитивног резултата релативно ниска (једноставна даља инспекција), најприкладнији тест је онај са ниском статистичком специфичношћу, али високом статистичком осетљивошћу (онај који дозвољава високу стопу лажних позитивних резултата у замену за минималне лажне негативне резултате).
На пример, у случају филтрирања спама, хипотеза је да имејл није спам.
Дакле, нулта хипотеза: „Имејл јесте спам“.
Грешка типа I (лажно позитивно): „Технике за филтрирање или блокирање спама погрешно класификују стварне имејлове као спам, и зато ометају њихову доставу“.
Док већина техника против спама имају могућност да блокирају велики проценат нежељених имејлова, тешко је да то учине без знатне количине лажно-позитивних резултата.
Грешка типа II (лажно негативно): „Спам имејлови нису детектовани као спам, већ се класификују као стварни имејлови“. Ниска количина лажних негативних резултата је индикатор ефикасности технологија за филтрирање спама.
^NEYMAN, J. (1928). "On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I". PEARSON, E. S. Biometrika. стр. 175—240.
^C.I.K.F. (јул 1951). "Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]". Journal of the Staple Inn Actuarial Society. стр. 243—244.CS1 одржавање: Формат датума (веза)
^Imajte na umu da indeks u izrazu H0 je nula (označava null), a nije „O“ (označava original)
^NEYMAN, J. (30. 10. 1933). "The testing of statistical hypotheses in relation to probabilities a priori". PEARSON, E. S. Mathematical Proceedings of the Cambridge Philosophical Society. стр. 492—510.CS1 одржавање: Формат датума (веза)
^Fisher, R.A. (1966). The design of experiments. (8th edition изд.). Hafner:Edinburgh.CS1 одржавање: Текст вишка (веза)
Betz, M.A. & Gabriel, K.R., "Type IV Errors and Analysis of Simple Effects", Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
David, F.N., "A Power Function for Tests of Randomness in a Sequence of Alternatives", Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
Gambrill, W., "False Positives on Newborns' Disease Tests Worry Parents", Health Day, (5 June 2006). Archived 17 May 2018 at the Wayback Machine
Kimball, A.W., "Errors of the Third Kind in Statistical Consulting", Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
Lubin, A., "The Interpretation of Significant Interaction", Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
Marascuilo, L.A. & Levin, J.R., "Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors", American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
Mitroff, I.I. & Featheringham, T.R., "On Systemic Problem Solving and the Error of the Third Kind", Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
Mosteller, F., "A k-Sample Slippage Test for an Extreme Population", The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.